
以下は著者本人(AGI HUB共同代表)による note 掲載記事の全文です。原文(note)はこちら。
追記:投げ銭をお送りいただいたかた,ありがとうございます!励みになります!
バズワードを無理矢理詰め込んだみたいなタイトルになっちゃいましたが,本当の話です(笑)
一般のかた(研究者以外)向けの解説
(研究者向けの解説は下にあります)
スタンフォード大やfacebook系研究所の一流研究者たちが,GPT-4oに研究者の役割を与えて議論させたんですね!
そしたらGPT-4oは,新型コロナ最新株の薬の素材候補を見つけちゃったんです!
どうやって見つけたの?
GPT-4oは,ノーベル賞にもなったAlphaFoldっていうソフトなどを駆使して見つけることができました!
人間じゃないと使いこなすのは難しそうと思われてたんで,驚きですね!
人間はどのくらい指示を出したの?
研究者の役割を一部与えること,GPT-4o同士の議論の大まかな議題を最初に示すこと,あとささいな部分の情報提供,そのくらいです!
割合にして,なんとたった1%くらい!
この結果をもとにして,コロナの新しい薬ができるまではどれくらいかかるの?
これは正直まだかかるかもですねー.
まだ薬としての調査をする前の段階なので,普通の薬だとしたら10年とかかかるし,コロナ薬なので優先されるとしても数年とかはかかりそう.
でも今回の研究結果がなかったら,さらに追加で1年2年とか必要になってたかもしれません!
GPT-4oが自動でいろいろやってくれたおかげです!
早く実用化して欲しいですね!
※ 以下は研究者向けの解説です ※
自分は部分的に専門だったり専門外だったりするので,内容に違和感があったら気軽にご意見ぶん投げてください.
(自分は元々は医師で,今はML系国際トップカンファや人工知能学会などで「LLMを活用した科学の自動化」のセッションを開催するために奔走してたりしてなかったりします.詳細は最後に)
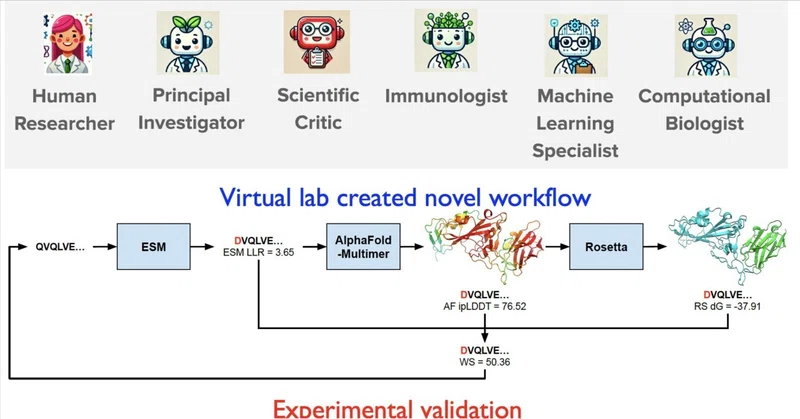
今回の研究成果の雑な概観

引用元:最終著者のtwitter
図上:LLMにいろんな役職を与えたよ
図中:LLMが既存のツール複数をいい感じに組み合わせたよ
図下左:赤◯が低かった(コロナ最新株に対応できなかった)けど,今回見つけた赤●は上がってて良さげ
図下右:ピンク色と赤の囲みが,今回見つけた部分だよ
(これらの詳細はまた後ほど解説…)
三行(?)でまとめると…
スタンフォード大やfacebook系研究所の先生たちが,GPT-4oに役割を与えて議論させたら,
AlphaFoldなどを駆使して,新型コロナ最新株の薬の素材候補を見つけてしまった!
事例報告的であって汎用性の検証がないとはいえ,現実の実験室でもいくつか検証実験しており説得力高し!
論文の著者情報
そこそこ強い人達がやってんなぁ,って感じです.
所属はスタンフォード大やChan Zuckerberg Biohub(旧facebook・現MetaのCEOザッカーバーグ夫妻による研究所)
Kyle Swanson 被引用5,000弱 深層学習を使った抗生剤発見や画像診断など(かがく を かそく せよ)
Wesley Wu 被引用2,000弱 マラリアのデータセットや抗体の人工進化など(なにそれおもしろそう)
Nash L. Bulaong 論文なし?John E. Pak研究室の研究員
John E. Pak 被引用4,000強 SARS-CoV-2関連で様々な研究
James Zou 被引用45,000弱 遺伝子解析,医療とAI全般,AIの偏見など(つえぇなぁ)
手法
雑に言うと,LLMに役職を設定(半分以上は自動で設定)した後に,段階を踏んで実験計画を議論させ,それを実際に実行させる,って感じです.
細かい部分は,まぁ研究に馴染みあるかたなら概ね妥当な感じに思えるんじゃないですかね?知らんけど()
手法を示している図1, 2について解説していきますね.
前者がミーティングのミクロな要素,後者がマクロな要素になっています.
図1:LLMの役職と,基本的なミーティングの形式

出典:論文本文図1
図1a:各役職の設定
まず人間(左側のピンク髪)が,主任研究者(葉っぱの奴)と評価者(赤い奴)を定義します.
各役職を定義する時は,専門分野,目標,役割も同時に定義します.
主任研究者役のLLMは,人間から聞いたプロジェクト概要を元にして自分で考え,他の専門家(右側の,縦に並んでいる3人)を同様に定義します.
なお評価者という立場は,ちょっと研究者でもピンとこないかもしれません.
便宜上の役割と思ってもらうのが良いとは思います.
具体的には,各研究者の提案に対して,建設的なフィードバックを行い洗練させる役目です.
図1b:チームミーティング
人間の研究者が議題を設定し,主任研究者が初期の考えと議題に関する質問を提示します.
その後,各専門家が応答し,評価者がフィードバック,主任研究者が議論を統合し次の質問を提示,というのをNラウンド実施します.
最後に主任研究者が議論をまとめ、最終的な回答を生成します.
図1c:個別ミーティング
人間の研究者が議題を与え,それに対して担当する専門家エージェントが回答,更に評価者がフィードバックします.
N回のラウンドを通じて回答を改善します.
図2:ミーティングの段階

出典:論文本文図2
順に,(a) チーム構成の確立,(b) プロジェクト仕様の検討,(c) AlphaFoldなどのツールの選択,(d) ツールの実装,(e) ワークフロー設計,というかたちで,LLM同士でのミーティングが行われていきます.
(a) チーム構成の確立
図1aと同じなので割愛
(b) プロジェクト仕様の検討
まず人間から,「新型コロナの最新変異株に対する抗体またはナノボディ(抗体のパーツ)を開発せよ」という指示が与えられます.
(新型コロナ変異株・抗体・ナノボディ・使用するツールの具体的な名称は,人間からは与えない状況です.またこれが開発できると,治療薬に応用できます)
その状態で,「抗体かナノボディのどちらを作るか」「どの抗体orナノボディを改造して作るか」などのチームミーティングが行われます.
議題自体は人間が与えていますが,工夫次第でここも自動化できそうですね.
単純に挙動を安定させるため一応人間が与えた,くらいの認識が良さそうに思います.
(c) AlphaFoldなどのツールの選択
別のチームミーティングでナノボディ設計に使用するツールを議論します.
人間は,最初に「ナノボディの設計に必要なツールを検討しましょう」のような大まかな議題を与えるのみです.以下同様&これも自動化できそう.
(d) ツールの実装
機械学習専門家(歯車の奴)と計算生物学者(ビーカーの奴)が,評価者(赤い奴)との個別ミーティングで実装を担当します.
(e) ワークフロー設計
主任研究者(葉っぱの奴)の人間との個別ミーティングで,ワークフローの構造や,評価指標の設計などを行います.
人間が与えた情報は,実行時間の制約や各ツールの基準値など,末節な内容のみのようです.
結果
図はいろいろありますが,抜粋して図5と補足図5, 補足図6を解説します.
図5がリアルワールドでの検証,補足図5がその一部の詳細,補足図6が人間の発言割合についての図です.
図5:現実での検証実験の結果

出典:論文本文図5
図5A:ナノボディの発現レベル
次の補足図5でまとめて説明します.
図5B:結合しやすさ
ELISAという実験の結果です.
縦軸が結合強度,横軸が様々なタンパク質(新型コロナなど)です.
各点が,LLMらによって予測されたナノボディたちです.
黒点が元のナノボディで,比較対照になります.
ピンク系の点は非特異的な結合で,BSA(陰性対照)のところで上がってしまうと望ましくないです(一番左のH11-D4のように).
緑点が特異的な結合です.
中2つのNb21やTy1では,JN.1という新型コロナ変異株について明らかに上がっている=結合するようになっているのがわかります.
またNb21は,KP.3(という変異株)についても上がっています.図ではわずかなのですが,統計的には明らかに異なり(0.1程度に対する3.5),弱い結合能は獲得したと言えるようです.
KP.3は最新の変異株なので,大きく上がるのが理想ではありましたが,多少でもほぼゼロとは全く違います.
干し草の中から針を探すような状況で,ほとんどAI任せのシステムが,将来につながる候補を見つけられたのは,快挙と言って良いでしょう.
今後の改良にも期待です(より良いナノボディという意味でも,より優秀なLLMの研究者集団という意味でも).
図5C:図5Bの一部のより詳細な分析
有望なナノボディ変異体(Nb21変異体とTy1変異体)について,水で薄めてみて細かく分析しています.
縦軸は同じで,横軸は希釈濃度です.
図5D:変異の位置と構造
変異体を可視化したものです.
ピンク色と赤の囲みが変異した部分です.
半数以上がオレンジ色の部分(相補性決定領域,CDRループ)となっています.
ここは(新型コロナなどの)抗原を認識するために直接関わる重要な領域なので,その部分での変異が多いというのは納得感がありますね.
補足図5:ナノボディの生成量と可溶性の評価

出典:論文本文補足図5
タンパク質電気泳動という実験の結果です.
これを見ると,あぁ,ほんとにリアルワールドでの検証実験もしたんだなぁ,って感じがしますね笑
横軸方向に,LLMらによって予測された各ナノボディを並べています.
縦軸が分子の大きさで,赤枠の位置が,ナノボディに相当する分子量15kDaです.
ここにバンド(黒い帯)があると,正しくナノボディが作られたということがわかります.
バンドは明瞭であるほど水に溶けやすいことを示し,精製が容易だったり体内で機能しやすかったりします.
バンドの色の濃さは,どのくらい発現(≒生成)しているかを意味します.図5Aと照らし合わせてみましょう.
図5Aは横軸が発現レベル=色の濃さで,濃いほど数字が大きいです.縦軸が当該発現レベルに当てはまる数になります.
確かにものすごく濃いのが10程度,比較的濃いのも30程度あり,ほとんど出ていないのは5,6くらいであることがわかりますね.
なお補足図5の黄色のハイライトは,ある種のベースラインです.
既知のナノボディであり,この検証実験が正しく機能していることや,他との比較に使えます.
補足図6:役職ごとの発言量

出典:論文本文補足図6
様々なミーティングにおける発言量で,青い部分が人間による入力トークン数(≒文字数),それ以外がLLMです.
また図には含まれていませんが,全体では人間の入力はわずか1.3%で,更にその中にはコピペも含まれています.
かなりの部分が自動化できていることがわかるかと思います.
結論
特定事例の報告的な研究ではありますが,LLMたちがAlphaFoldなどを駆使して,新型コロナの最新株に対するナノボディ(治療薬に応用できる)候補を見つけてしまった,そして現実での検証もクリアしたということが,なんとなくおわかりいただけたかと思います.
個人的な余談
最初にもちらっと書きましたが,自分はML系国際トップカンファや人工知能学会などで,「LLMを活用した科学の自動化」のセッションを開催しようとしています.
この分野,今年8月のSakana AIのThe AI Scientist(仮説生成,実験,論文執筆まで全て自動化)を皮切りに,急速に注目を浴びつつあります(まさか自分もこんなところに身を置くことになるとは…!).
参入するには今のうちがチャンスですし,(元Google社員らが立ち上げた)Sakana AIが日本発スタートアップ・日本最速ユニコーン企業というのもアツいポイントです!
ご興味あるかたはぜひnoteなりtwitterなりフォローしていただければと.
(基本的にはALIGNという団体のSlackのいちチャンネルでわちゃわちゃしています)
え?Science of Scienceはどうした,って?
まぁまぁ,見ててくださいよ…()
※ 例の翻訳書は校正が進んでおりますので,もうしばしお待ちください…!